日志
1.1 作用:
跟输出语句一样,可以把程序在运行过程中的详细信息都打印在控制台上。
利用log日志还可以把这些详细信息保存到文件和数据库中。
1.2 使用步骤:
不是java的,也不是自己写的,是第三方提供的代码,所以我们要导入jar包。
把第三方的代码导入到当前的项目当中
新建lib文件夹,把jar粘贴到lib文件夹当中,全选后右键点击选择add as a ....
检测导入成功:导入成功后jar包可以展开。在项目重构界面可以看到导入的内容
把配置文件粘贴到src文件夹下
在代码中获取日志对象
调用方法打印日志
1.3 日志级别
TRACE, DEBUG, INFO, WARN, ERROR还有两个特殊的:
ALL:输出所有日志
OFF:关闭所有日志
日志级别从小到大的关系:
TRACE < DEBUG < INFO < WARN < ERROR
1.4 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--
CONSOLE :表示当前的日志信息是可以输出到控制台的。
-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!--输出流对象 默认 System.out 改为 System.err-->
<target>System.out</target>
<encoder>
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度
%msg:日志消息,%n是换行符-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%-5level] %c [%thread] : %msg%n</pattern>
</encoder>
</appender>
<!-- File是输出的方向通向文件的 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
<!--日志输出路径-->
<file>C:/code/itheima-data.log</file>
<!--指定日志文件拆分和压缩规则-->
<rollingPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!--通过指定压缩文件名称,来确定分割文件方式-->
<fileNamePattern>C:/code/itheima-data2-%d{yyyy-MMdd}.log%i.gz</fileNamePattern>
<!--文件拆分大小-->
<maxFileSize>1MB</maxFileSize>
</rollingPolicy>
</appender>
<!--
level:用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF
, 默认debug
<root>可以包含零个或多个<appender-ref>元素,标识这个输出位置将会被本日志级别控制。
-->
<root level="info">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE" />
</root>
</configuration>写在前面的话:
基础加强包含了:
反射,动态代理,类加载器,xml,注解,日志,单元测试等知识点
其中最难的是反射和动态代理,其他知识点都非常简单
由于B站P数限制,xml,注解等知识点,阿玮写了详细文档供大家学习
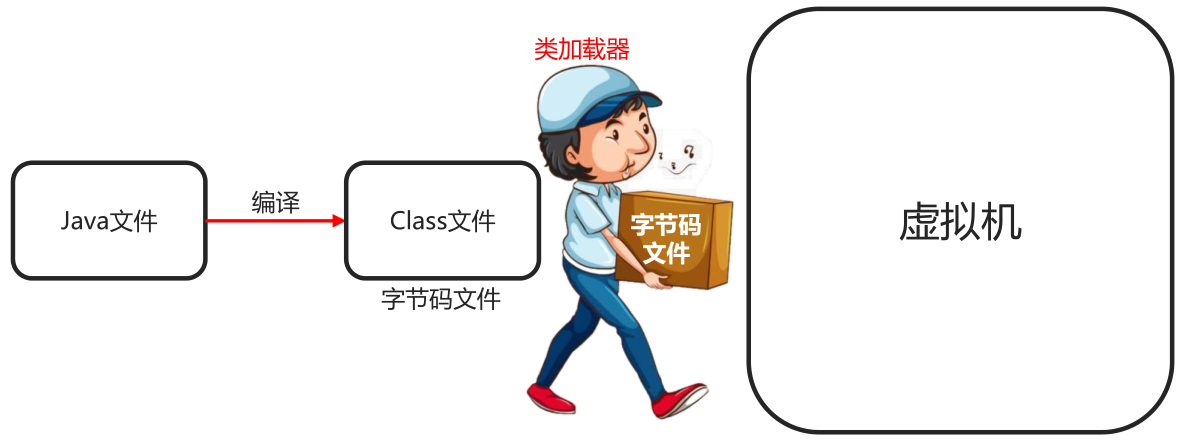
2.类加载器
2.1类加载器
作用
负责将.class文件(存储的物理文件)加载在到内存中
2.2类加载的完整过程
类加载时机
简单理解:字节码文件什么时候会被加载到内存中?
有以下的几种情况:
- 创建类的实例(对象)
- 调用类的类方法
- 访问类或者接口的类变量,或者为该类变量赋值
- 使用反射方式来强制创建某个类或接口对应的java.lang.Class对象
- 初始化某个类的子类
- 直接使用java.exe命令来运行某个主类
总结而言:用到了就加载,不用不加载
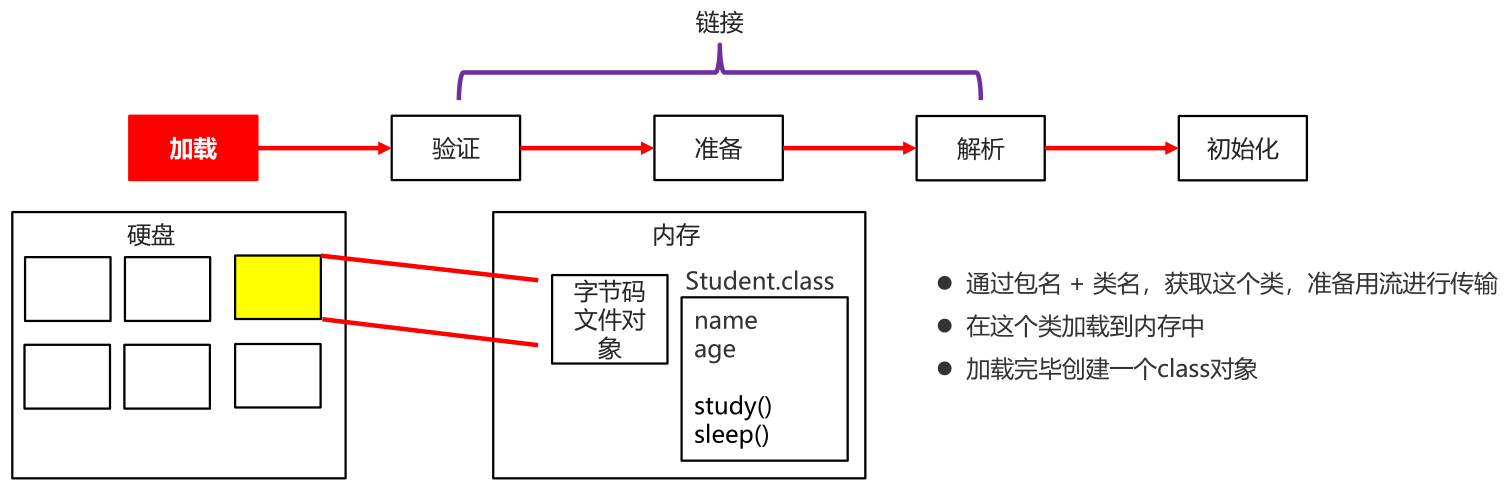
类加载过程
加载
- 通过包名 + 类名,获取这个类,准备用流进行传输
- 在这个类加载到内存中
- 加载完毕创建一个class对象
链接
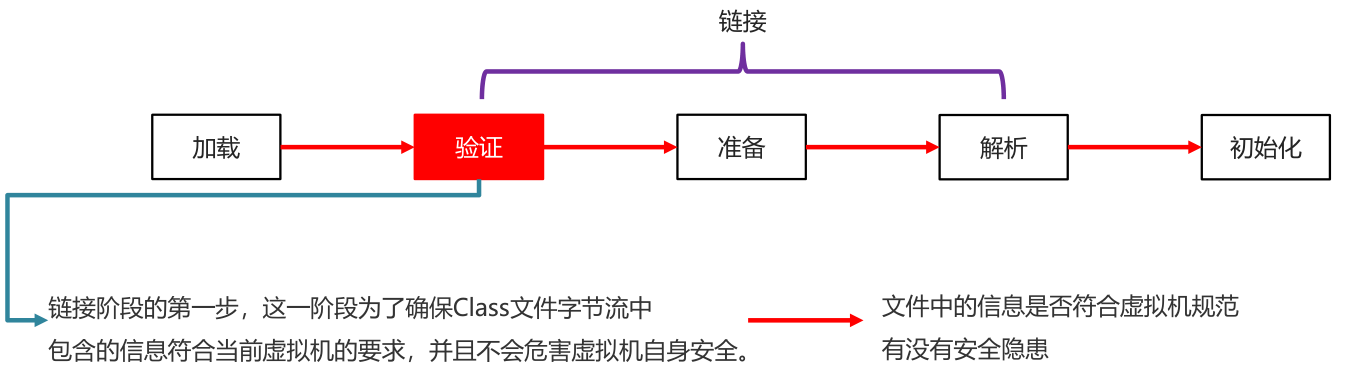
验证
确保Class文件字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身安全
(文件中的信息是否符合虚拟机规范有没有安全隐患)
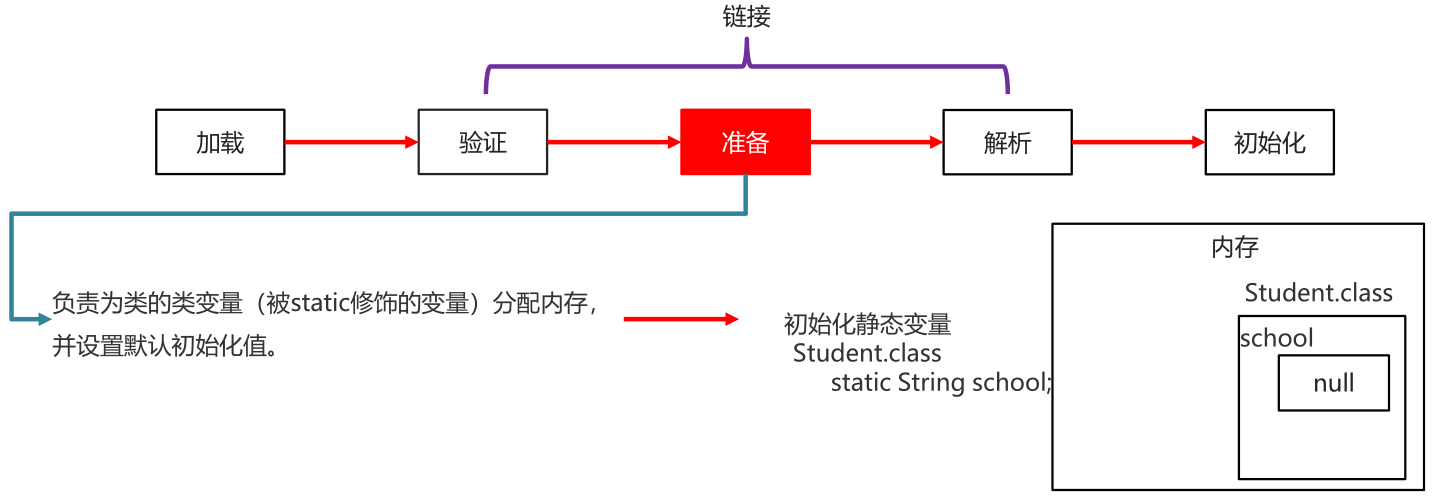
准备
负责为类的类变量(被static修饰的变量)分配内存,并设置默认初始化值
(初始化静态变量)
解析
将类的二进制数据流中的符号引用替换为直接引用
(本类中如果用到了其他类,此时就需要找到对应的类)
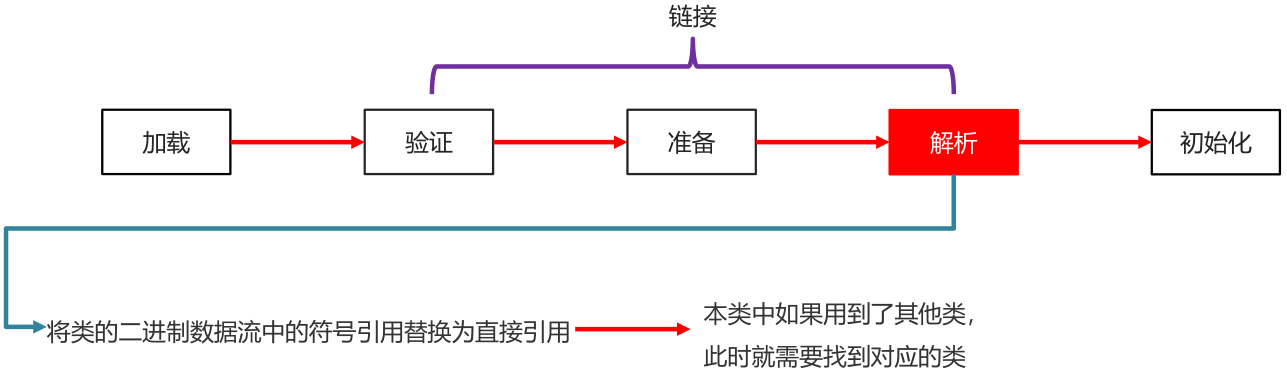
初始化
根据程序员通过程序制定的主观计划去初始化类变量和其他资源
(静态变量赋值以及初始化其他资源)
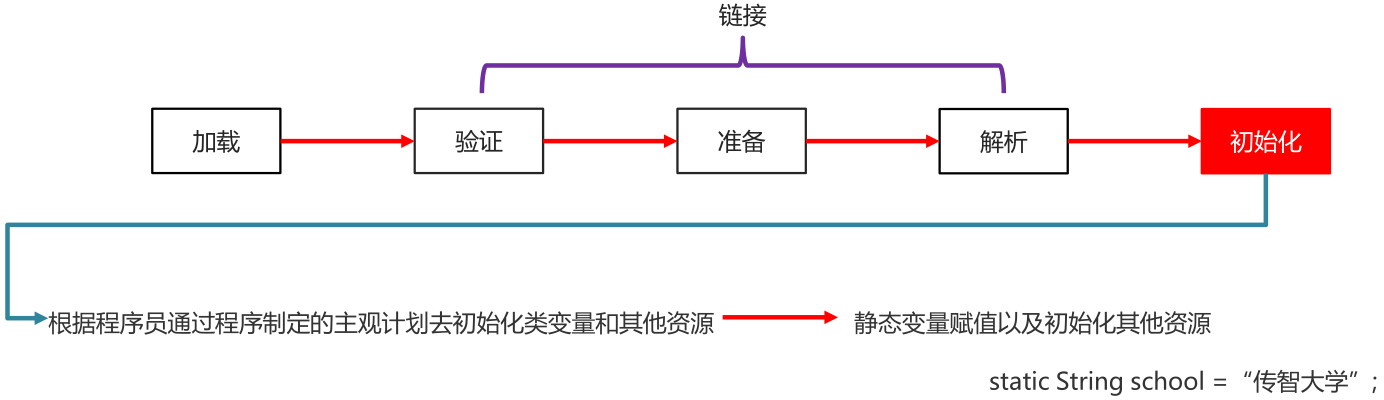
小结
- 当一个类被使用的时候,才会加载到内存
- 类加载的过程: 加载、验证、准备、解析、初始化
2.3类加载的分类【理解】
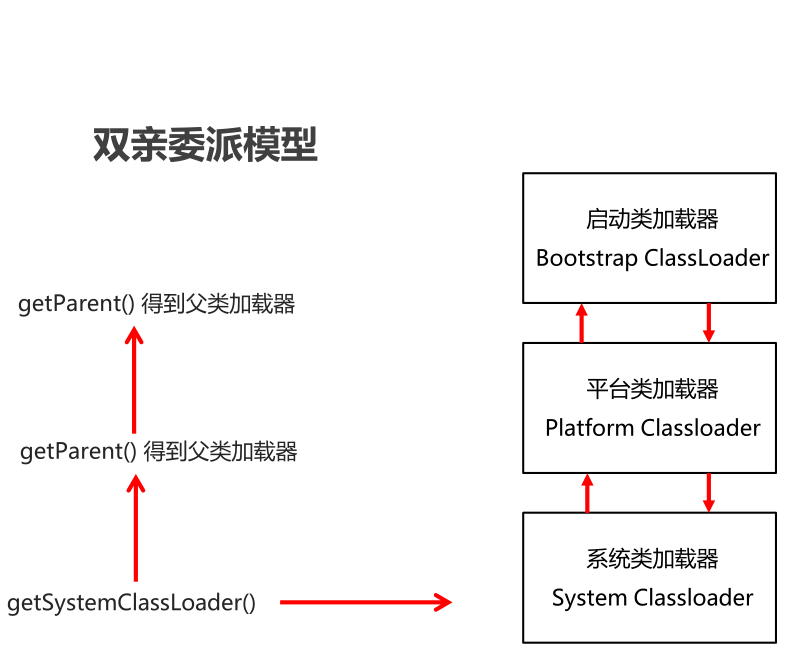
分类
- Bootstrap class loader:虚拟机的内置类加载器,通常表示为null ,并且没有父null
- Platform class loader:平台类加载器,负责加载JDK中一些特殊的模块
- System class loader:系统类加载器,负责加载用户类路径上所指定的类库
类加载器的继承关系
- System的父加载器为Platform
- Platform的父加载器为Bootstrap
代码演示
javapublic class ClassLoaderDemo1 { public static void main(String[] args) { //获取系统类加载器 ClassLoader systemClassLoader = ClassLoader.getSystemClassLoader(); //获取系统类加载器的父加载器 --- 平台类加载器 ClassLoader classLoader1 = systemClassLoader.getParent(); //获取平台类加载器的父加载器 --- 启动类加载器 ClassLoader classLoader2 = classLoader1.getParent(); System.out.println("系统类加载器" + systemClassLoader); System.out.println("平台类加载器" + classLoader1); System.out.println("启动类加载器" + classLoader2); } }
2.4双亲委派模型【理解】
介绍
如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式
2.5ClassLoader 中的两个方法【应用】
方法介绍
方法名 说明 public static ClassLoader getSystemClassLoader() 获取系统类加载器 public InputStream getResourceAsStream(String name) 加载某一个资源文件 示例代码
javapublic class ClassLoaderDemo2 { public static void main(String[] args) throws IOException { //static ClassLoader getSystemClassLoader() 获取系统类加载器 //InputStream getResourceAsStream(String name) 加载某一个资源文件 //获取系统类加载器 ClassLoader systemClassLoader = ClassLoader.getSystemClassLoader(); //利用加载器去加载一个指定的文件 //参数:文件的路径(放在src的根目录下,默认去那里加载) //返回值:字节流。 InputStream is = systemClassLoader.getResourceAsStream("prop.properties"); Properties prop = new Properties(); prop.load(is); System.out.println(prop); is.close(); } }
3.xml
3.1概述【理解】
万维网联盟(W3C)
万维网联盟(W3C)创建于1994年,又称W3C理事会。1994年10月在麻省理工学院计算机科学实验室成立。 建立者: Tim Berners-Lee (蒂姆·伯纳斯·李)。 是Web技术领域最具权威和影响力的国际中立性技术标准机构。 到目前为止,W3C已发布了200多项影响深远的Web技术标准及实施指南,
如广为业界采用的超文本标记语言HTML(标准通用标记语言下的一个应用)、
可扩展标记语言XML(标准通用标记语言下的一个子集)
以及帮助残障人士有效获得Web信息的无障碍指南(WCAG)等

xml概述
XML的全称为(EXtensible Markup Language),是一种可扩展的标记语言 标记语言: 通过标签来描述数据的一门语言(标签有时我们也将其称之为元素) 可扩展:标签的名字是可以自定义的,XML文件是由很多标签组成的,而标签名是可以自定义的
作用
- 用于进行存储数据和传输数据
- 作为软件的配置文件
作为配置文件的优势
- 可读性好
- 可维护性高
3.2标签的规则【应用】
标签由一对尖括号和合法标识符组成
java<student>标签必须成对出现
java<student> </student> 前边的是开始标签,后边的是结束标签特殊的标签可以不成对,但是必须有结束标记
java<address/>标签中可以定义属性,属性和标签名空格隔开,属性值必须用引号引起来
java<student id="1"> </student>标签需要正确的嵌套
java这是正确的: <student id="1"> <name>张三</name> </student> 这是错误的: <student id="1"><name>张三</student></name>
3.3语法规则【应用】
语法规则
XML文件的后缀名为:xml
文档声明必须是第一行第一列
<?xml version="1.0" encoding="UTF-8" standalone="yes”?>version:该属性是必须存在的 encoding:该属性不是必须的 打开当前xml文件的时候应该是使用什么字符编码表(一般取值都是UTF-8)
standalone: 该属性不是必须的,描述XML文件是否依赖其他的xml文件,取值为yes/no
必须存在一个根标签,有且只能有一个
XML文件中可以定义注释信息
XML文件中可以存在以下特殊字符
java< < 小于 > > 大于 & & 和号 ' ' 单引号 " " 引号XML文件中可以存在CDATA区
<![CDATA[ …内容… ]]>
示例代码
xml<?xml version="1.0" encoding="UTF-8" ?> <!--注释的内容--> <!--本xml文件用来描述多个学生信息--> <students> <!--第一个学生信息--> <student id="1"> <name>张三</name> <age>23</age> <info>学生< >>>>>>>>>>>的信息</info> <message> <![CDATA[内容 <<<<<< >>>>>> ]]]></message> </student> <!--第二个学生信息--> <student id="2"> <name>李四</name> <age>24</age> </student> </students>
3.4xml解析【应用】
概述
xml解析就是从xml中获取到数据
常见的解析思想
DOM(Document Object Model)文档对象模型:就是把文档的各个组成部分看做成对应的对象。 会把xml文件全部加载到内存,在内存中形成一个树形结构,再获取对应的值
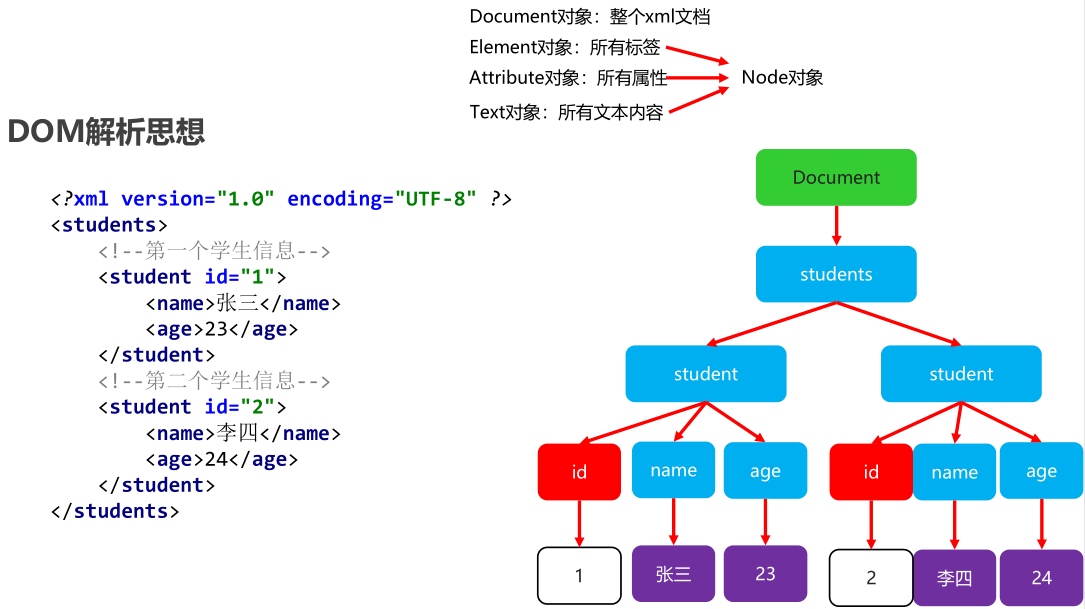
常见的解析工具
- JAXP: SUN公司提供的一套XML的解析的API
- JDOM: 开源组织提供了一套XML的解析的API-jdom
- DOM4J: 开源组织提供了一套XML的解析的API-dom4j,全称:Dom For Java
- pull: 主要应用在Android手机端解析XML
解析的准备工作
我们可以通过网站:https://dom4j.github.io/ 去下载dom4j
今天的资料中已经提供,我们不用再单独下载了,直接使用即可
将提供好的dom4j-1.6.1.zip解压,找到里面的dom4j-1.6.1.jar
在idea中当前模块下新建一个libs文件夹,将jar包复制到文件夹中
选中jar包 -> 右键 -> 选择add as library即可
需求
- 解析提供好的xml文件
- 将解析到的数据封装到学生对象中
- 并将学生对象存储到ArrayList集合中
- 遍历集合
代码实现
java<?xml version="1.0" encoding="UTF-8" ?> <!--注释的内容--> <!--本xml文件用来描述多个学生信息--> <students> <!--第一个学生信息--> <student id="1"> <name>张三</name> <age>23</age> </student> <!--第二个学生信息--> <student id="2"> <name>李四</name> <age>24</age> </student> </students> // 上边是已经准备好的student.xml文件 public class Student { private String id; private String name; private int age; public Student() { } public Student(String id, String name, int age) { this.id = id; this.name = name; this.age = age; } public String getId() { return id; } public void setId(String id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Student{" + "id='" + id + '\'' + ", name='" + name + '\'' + ", age=" + age + '}'; } } /** * 利用dom4j解析xml文件 */ public class XmlParse { public static void main(String[] args) throws DocumentException { //1.获取一个解析器对象 SAXReader saxReader = new SAXReader(); //2.利用解析器把xml文件加载到内存中,并返回一个文档对象 Document document = saxReader.read(new File("myxml\\xml\\student.xml")); //3.获取到根标签 Element rootElement = document.getRootElement(); //4.通过根标签来获取student标签 //elements():可以获取调用者所有的子标签.会把这些子标签放到一个集合中返回. //elements("标签名"):可以获取调用者所有的指定的子标签,会把这些子标签放到一个集合中并返回 //List list = rootElement.elements(); List<Element> studentElements = rootElement.elements("student"); //System.out.println(list.size()); //用来装学生对象 ArrayList<Student> list = new ArrayList<>(); //5.遍历集合,得到每一个student标签 for (Element element : studentElements) { //element依次表示每一个student标签 //获取id这个属性 Attribute attribute = element.attribute("id"); //获取id的属性值 String id = attribute.getValue(); //获取name标签 //element("标签名"):获取调用者指定的子标签 Element nameElement = element.element("name"); //获取这个标签的标签体内容 String name = nameElement.getText(); //获取age标签 Element ageElement = element.element("age"); //获取age标签的标签体内容 String age = ageElement.getText(); // System.out.println(id); // System.out.println(name); // System.out.println(age); Student s = new Student(id,name,Integer.parseInt(age)); list.add(s); } //遍历操作 for (Student student : list) { System.out.println(student); } } }
3.5DTD约束【理解】
什么是约束
用来限定xml文件中可使用的标签以及属性
约束的分类
- DTD
- schema
编写DTD约束
步骤
创建一个文件,这个文件的后缀名为.dtd
看xml文件中使用了哪些元素
<!ELEMENT>可以定义元素判断元素是简单元素还是复杂元素
简单元素:没有子元素。 复杂元素:有子元素的元素;
代码实现
java<!ELEMENT persons (person)> <!ELEMENT person (name,age)> <!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)>
引入DTD约束
引入DTD约束的三种方法
引入本地dtd
<!DOCTYPE 根元素名称 SYSTEM ‘DTD文件的路径'>在xml文件内部引入
<!DOCTYPE 根元素名称 [ dtd文件内容 ]>引入网络dtd
<!DOCTYPE 根元素的名称 PUBLIC "DTD文件名称" "DTD文档的URL">
代码实现
引入本地DTD约束
xml// 这是persondtd.dtd文件中的内容,已经提前写好 <!ELEMENT persons (person)> <!ELEMENT person (name,age)> <!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)> // 在person1.xml文件中引入persondtd.dtd约束 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE persons SYSTEM 'persondtd.dtd'> <persons> <person> <name>张三</name> <age>23</age> </person> </persons>在xml文件内部引入
xml<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE persons [ <!ELEMENT persons (person)> <!ELEMENT person (name,age)> <!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)> ]> <persons> <person> <name>张三</name> <age>23</age> </person> </persons>引入网络dtd
xml<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE persons PUBLIC "dtd文件的名称" "dtd文档的URL"> <persons> <person> <name>张三</name> <age>23</age> </person> </persons>
DTD语法
定义元素
定义一个元素的格式为:
<!ELEMENT 元素名 元素类型>简单元素: EMPTY: 表示标签体为空
ANY: 表示标签体可以为空也可以不为空
PCDATA: 表示该元素的内容部分为字符串
复杂元素: 直接写子元素名称. 多个子元素可以使用","或者"|"隔开; ","表示定义子元素的顺序 ; "|": 表示子元素只能出现任意一个 "?"零次或一次, "+"一次或多次, "*"零次或多次;如果不写则表示出现一次

定义属性
格式
定义一个属性的格式为:
<!ATTLIST 元素名称 属性名称 属性的类型 属性的约束>属性的类型: CDATA类型:普通的字符串属性的约束:
// #REQUIRED: 必须的 // #IMPLIED: 属性不是必需的 // #FIXED value:属性值是固定的
代码实现
java<!ELEMENT persons (person+)> <!ELEMENT person (name,age)> <!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)> <!ATTLIST person id CDATA #REQUIRED> <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE persons SYSTEM 'persondtd.dtd'> <persons> <person id="001"> <name>张三</name> <age>23</age> </person> <person id = "002"> <name>张三</name> <age>23</age> </person> </persons> ```
3.6schema约束【理解】
schema和dtd的区别
- schema约束文件也是一个xml文件,符合xml的语法,这个文件的后缀名.xsd
- 一个xml中可以引用多个schema约束文件,多个schema使用名称空间区分(名称空间类似于java包名)
- dtd里面元素类型的取值比较单一常见的是PCDATA类型,但是在schema里面可以支持很多个数据类型
- schema 语法更加的复杂
编写schema约束
步骤
1,创建一个文件,这个文件的后缀名为.xsd。 2,定义文档声明 3,schema文件的根标签为:
<schema>4,在<schema>中定义属性: xmlns=http://www.w3.org/2001/XMLSchema 5,在<schema>中定义属性 : targetNamespace =唯一的url地址,指定当前这个schema文件的名称空间。 6,在<schema>中定义属性 : elementFormDefault="qualified“,表示当前schema文件是一个质量良好的文件。 7,通过element定义元素 8,判断当前元素是简单元素还是复杂元素
代码实现
java<?xml version="1.0" encoding="UTF-8" ?> <schema xmlns="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www.itheima.cn/javase" elementFormDefault="qualified" > <!--定义persons复杂元素--> <element name="persons"> <complexType> <sequence> <!--定义person复杂元素--> <element name = "person"> <complexType> <sequence> <!--定义name和age简单元素--> <element name = "name" type = "string"></element> <element name = "age" type = "string"></element> </sequence> </complexType> </element> </sequence> </complexType> </element> </schema>
引入schema约束
步骤
1,在根标签上定义属性xmlns="http://www.w3.org/2001/XMLSchema-instance" 2,通过xmlns引入约束文件的名称空间 3,给某一个xmlns属性添加一个标识,用于区分不同的名称空间 格式为: xmlns:标识=“名称空间地址” ,标识可以是任意的,但是一般取值都是xsi 4,通过xsi:schemaLocation指定名称空间所对应的约束文件路径 格式为:xsi:schemaLocation = "名称空间url 文件路径“
代码实现
java<?xml version="1.0" encoding="UTF-8" ?> <persons xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.itheima.cn/javase" xsi:schemaLocation="http://www.itheima.cn/javase person.xsd" > <person> <name>张三</name> <age>23</age> </person> </persons>
schema约束定义属性
代码示例
java<?xml version="1.0" encoding="UTF-8" ?> <schema xmlns="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www.itheima.cn/javase" elementFormDefault="qualified" > <!--定义persons复杂元素--> <element name="persons"> <complexType> <sequence> <!--定义person复杂元素--> <element name = "person"> <complexType> <sequence> <!--定义name和age简单元素--> <element name = "name" type = "string"></element> <element name = "age" type = "string"></element> </sequence> <!--定义属性,required( 必须的)/optional( 可选的)--> <attribute name="id" type="string" use="required"></attribute> </complexType> </element> </sequence> </complexType> </element> </schema> <?xml version="1.0" encoding="UTF-8" ?> <persons xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.itheima.cn/javase" xsi:schemaLocation="http://www.itheima.cn/javase person.xsd" > <person id="001"> <name>张三</name> <age>23</age> </person> </persons>
4. 单元测试Junit
4.1 什么是单元测试?(掌握)
对部分代码进行测试。
4.2 Junit的特点?(掌握)
是一个第三方的工具。(把别人写的代码导入项目中)(专业叫法:导jar包)
如果运行结果显示绿色,表示运行结果是正确的。
如果运行结果显示红色,表示运行结果是错误的。
4.3 基本用法:(掌握)
1,一定要先写一个方法。
2,在这个方法的上面写@Test
3,鼠标点一下@Test 按alt + 回车,点击Junit4
此时就可以自动导包。
如果自动导包失败(连接外网,或者自己手动导包)
如果导包成功在左下角就会出现Junit4的相关jar包
手动导包(掌握)
1,在当前模块下,右键新建一个文件夹(lib)
2,把今天资料里面的两个jar包,拷贝到lib文件夹里面
3,选中两个jar右键点击add as a lib....
4,到代码中,找到@Test,按alt + 回车,再来导入。
运行测试代码(掌握)
- 只能直接运行无参无返回值的非静态方法
- 想要运行谁,就右键点击哪个方法。如果想要运行一个类里面所有的测试方法,选择类名,有点点击即可。
Junit正确的打开方式(正确的使用方式)(掌握)
注意点:并不是直接在要测试的方法上面直接加@Test
原因:因为要测试的方法有可能是有参数的,有返回值,或者是静态的。
正确的使用方式:(掌握)
1,新建测试类
2,新建测试方法(要测试的方法名 + Test) methodTest
3,在这个方法中直接调用要测试的方法
4,在测试方法的上面写@Test
代码示例:
//真正用来测试的类
//测试用例(测试类)
public class JunitTest {
//在这个类里面再写无参无返回值的非静态方法
//在方法中调用想要测试的方法
@Test
public void method2Test(){
//调用要测试的方法
JunitDemo1 jd = new JunitDemo1();
jd.method2(10);
}
}实际开发中单元测试的使用方式(掌握)
需求:测试File中的delete方法,写的是否正确(掌握)
开发中的测试原则:
不污染原数据。
代码示例:
public class JunitDemo3 {
//在实际开发中,真正完整的单元测试该怎么写?
//前提:
//以后在工作的时候,测试代码不能污染原数据。(修改,篡改)
//1.利用Before去对数据做一个初始化的动作
//2.利用Test真正的去测试方法
//3.利用After去还原数据
//需求:测试File类中的delete方法是否书写正确???
@Before
public void beforemethod() throws IOException {
//先备份
File src = new File("C:\\Users\\moon\\Desktop\\a.txt");
File dest = new File("C:\\Users\\moon\\Desktop\\copy.txt");
FileInputStream fis = new FileInputStream(src);
FileOutputStream fos = new FileOutputStream(dest);
int b;
while((b = fis.read()) != -1){
fos.write(b);
}
fos.close();
fis.close();
}
//作为一个标准的测试人员,运行完单元测试之后,不能污染原数据
//需要达到下面两个要求:
//1.得到结果
//2.a.txt还在而且其他的备份文件消失
@Test
public void method(){
File file = new File("C:\\Users\\moon\\Desktop\\a.txt");
boolean delete = file.delete();
//检查a.txt是否存在
boolean exists = file.exists();
//只有同时满足了下面所有的断言,才表示delete方法编写正确
Assert.assertEquals("delete方法出错了",delete,true);
Assert.assertEquals("delete方法出错了",exists,false);
}
@After
public void aftermethod() throws IOException {
//还要对a.txt做一个还原
File src = new File("C:\\Users\\moon\\Desktop\\copy.txt");
File dest = new File("C:\\Users\\moon\\Desktop\\a.txt");
FileInputStream fis = new FileInputStream(src);
FileOutputStream fos = new FileOutputStream(dest);
int b;
while((b = fis.read()) != -1){
fos.write(b);
}
fos.close();
fis.close();
//备份数据要删除
src.delete();
}
}作业:
测试Properties类中的store方法是否书写正确?
开发心得:
1.Before 准备数据
2.Test 测试方法
3.After 还原
Before
准备数据
1.创建Properties的对象
2.put数据到集合当中
//只不过在下面的方法中,我们也需要用到Properties的对象,所以写完之后要挪到成员位置Test
调用store方法,保存数据到本地文件
断言1:
判断当前文件是否存在
断言2:
文件的大小一定是大于0
断言3:
再次读取文件中的数据,判断是否跟集合中一致
结论:
如果所有的断言都通过了,表示store方法是正确的After
把本地文件给删除扩展点:
在单元测试中,相对路径是相对当前模块而言的。
代码示例:
File file = new File("aweihaoshuai.txt");
file.createNewFile();
//此时是把aweihaoshuai.txt这个文件新建到模块中了。5. 注解
5.1 注释和注解的区别?(掌握)
共同点:都可以对程序进行解释说明。
不同点:注释,是给程序员看的。只在Java中有效。在class文件中不存在注释的。
当编译之后,会进行注释擦除。
注解,是给虚拟机看的。当虚拟机看到注解之后,就知道要做什么事情了。
5.2 如何使用注解(掌握)
在以前看过注解@Override。
当子类重写父类方法的时候,在重写的方法上面写@Override。
当虚拟机看到@Override的时候,就知道下面的方法是重写的父类的。检查语法,如果语法正确编译正常,如果语法错误,就会报错。
5.3 Java中已经存在的注解(掌握)
@Override:表示方法的重写
@Deprecated:表示修饰的方法已过时
@SuppressWarnings("all"):压制警告
除此之外,还需要掌握第三方框架中提供的注解:
比如:Junit
@Test 表示运行测试方法
@Before 表示在Test之前运行,进行数据的初始化
@After 表示在Test之后运行,进行数据的还原
5.4 自定义注解(了解)
自定义注解单独存在是没有什么意义的,一般会跟反射结合起来使用,会用发射去解析注解。
针对于注解,只要掌握会使用别人已经写好的注解即可。
关于注解的解析,一般是在框架的底层已经写好了。
5.5 特殊属性(掌握)
value:
当注解中只有"一个属性",并且属性名是"value",使用注解时,可以省略value属性名
代码示例:
//注解的定义
public @interface Anno2 {
public String value();
public int age() default 23;
}
//注解的使用
@Anno2("123")
public class AnnoDemo2 {
@Anno2("123")
public void method(){
}
}5.6 元注解(了解)
可以写在注解上面的注解
@Target :指定注解能在哪里使用
@Retention :可以理解为保留时间(生命周期)
Target:
作用:用来标识注解使用的位置,如果没有使用该注解标识,则自定义的注解可以使用在任意位置。
可使用的值定义在ElementType枚举类中,常用值如下
- TYPE,类,接口
- FIELD, 成员变量
- METHOD, 成员方法
- PARAMETER, 方法参数
- CONSTRUCTOR, 构造方法
- LOCAL_VARIABLE, 局部变量
Retention:
作用:用来标识注解的生命周期(有效范围)
可使用的值定义在RetentionPolicy枚举类中,常用值如下
- SOURCE:注解只作用在源码阶段,生成的字节码文件中不存在
- CLASS:注解作用在源码阶段,字节码文件阶段,运行阶段不存在,默认值
- RUNTIME:注解作用在源码阶段,字节码文件阶段,运行阶段
注解的解析:
5.7 模拟JUnit自带的@Test注解(了解)
代码示例:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface MyTest {
}
public class MyTestMethod {
@MyTest
public void method1(){
System.out.println("method1");
}
public void method2(){
System.out.println("method2");
}
@MyTest
public void method3(){
System.out.println("method3");
}
}
public class MyTestDemo {
public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException, InvocationTargetException {
//1,获取class对象
Class clazz = Class.forName("com.itheima.test2.MyTestMethod");
//获取对象
Object o = clazz.newInstance();
//2.获取所有方法
Method[] methods = clazz.getDeclaredMethods();
for (Method method : methods) {
//method依次表示类里面的每一个方法
method.setAccessible(true);
//判断当前方法有没有MyTest注解
if(method.isAnnotationPresent(MyTest.class)){
method.invoke(o);
}
}
}
}5.8 注解小结:
掌握如何使用已经存在的注解即可。
@Override:表示方法的重写
@Deprecated:表示修饰的方法已过时
@SuppressWarnings("all"):压制警告
@Test:表示要运行的方法
在以后的实际开发中,注解是使用框架已经提供好的注解。
自定义注解+解析注解(很难的,了解),一般会出现在框架的底层。当以后我们要自己写一个框架的时候,才会用到自定义注解+解析注解。